Setting up Python for Data Science on M1 Mac
I recently bought a M1 Macbook Air, i found it quite difficult to get all my libraries working, so i thought i’d explain how i got them working.
There are multiple ways to install python
- Through Homebrew
- Through Miniforge
- Anaconda Via Rosetta
- Install from python website
After a couple of tests, i found Rosetta version to be quite slow compared with both the native version of python as well as python running on my linux machine (Intel 10th gen). I also found out that miniforge was the easiest way to install.
Step 1: Install Xcode command line tools
xcode-select --install
Step 2: Install Homebrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
Step 3: Install Miniforge
You can install miniforge either from brew or via miniforge on github.
brew install miniforge
github — GitHub — conda-forge/miniforge: A conda-forge distribution.
Step 4: Install the required libraries
Miniforge comes with python 3.9. Based on the libraries you need, you might want to downgrade python for compatibility. This was the case for me, so i downgraded to 3.8
conda install python=3.8
You might want to create new environment as well.
conda create -n [env name here] conda activate [env name here] conda install python=3.8
For the libraries, you can just conda install or pip install if the library is not available in conda.
If you have a lot of libraries that you want to install you can put them in a requirement.txt file and use
cat requirements.txt | xargs -n 1 conda install
This will prevent conda from failing because of a single library.
After this, you can try pip install the libraries that weren’t installed by conda.
You can know these libraries by using
conda install --file requirements.txt
Most of the popular libraries like tensorflow, sklearn, pandas etc work right out of the box. Some obscure libraries might not work, you can try installing from source if it happens or find an alternatives. One of the libraries pykrige did not get installed but i found out that GaussianProcess in sklearn does the same thing.
However, i had two main problems.
- pycaret did not install since it had a hard requirement of a scipy version that doesn’t work with M1.
- XGBoost threw segmentation fault when XGBClassifier().fit() was called.
I did find workarounds and it might work for you as well.
Workaround 1: Installing Pycaret
Step 1: Install pycaret without dependencies
pip install --no-dependencies pycaret
Step 2: Installing the requirements
pycaret/requirements.txt at master · pycaret/pycaret · GitHub contains requirements for pycaret
I removed version requirements for all packages containing < or <= or ==
pandas
scipy
numpy
seaborn
matplotlib
IPython
joblib
scikit-learn
ipywidgets
yellowbrick>=1.0.1
lightgbm>=2.3.1
plotly>=4.4.1
wordcloud
textblob
cufflinks>=0.17.0
umap-learn
pyLDAvis
gensim
spacy
nltk
mlxtend>=0.17.0
pyod
pandas-profiling>=2.8.0
kmodes>=0.10.1
mlflow
imbalanced-learn
scikit-plot #for lift and gain charts
Boruta
numbai named the file pycaret_requirements.txt and installed dependencies using
cat pycaret_requirements.txt | xargs -n 1 conda install
for all the packages that did not get installed, i pip installed it.
Workaround 2: Installing XGBoost
You might have to install cmake, libomp if not already installed.
brew install cmake libomp
I got XGBoost working by using — no-binary option
pip install xgboost --no-binary xgboost -v
If you still get segmentation fault, try removing libomp and reinstalling xgboost using the above command.
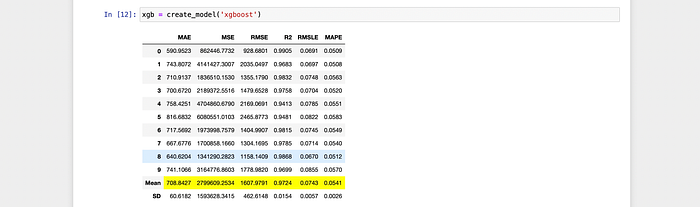
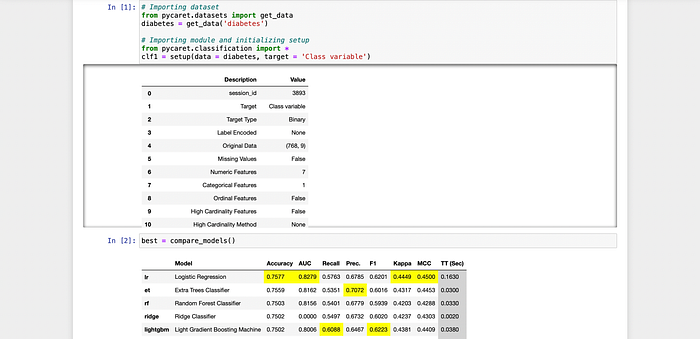
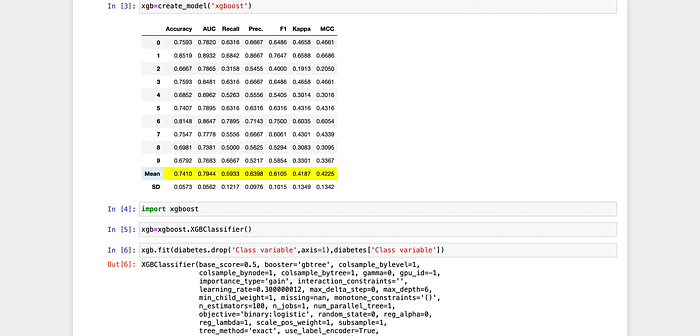
Testing
I ran both classification and regression example from pycaret and it worked well.
I’ve attached a few screenshots
Classification:
Regression: